
What does it mean to Train a Neural Network used in Generative Artificial Intelligence
and why it will change the nature of copyrights and intellectual property
Bart Binning, Ed.D.
Data that is stored on paper, or in databases or other computer files, are identifiably discreet with multiple levels of granularity where data can be uniquely identified, attributed, and sourced. On the other hand, data stored in a neural network is ubiquitous; it’s source is difficult be uniquely identified and once integrated into the neural network, the information is difficult to be removed. By its nature, data integrated into a neural network is an approximation, not precise.
Today, when we think of artificial intelligence, (especially a Generative AI programs such as OpenAI’s Chat GPT and DALL-E, Google’s BERT, Meta’s CodeCompose, etc.) we are discussing a type of a software application using a neural network backbone. A neural network is an application that uses nodes (or neurons) that are interconnected in a multilayered structure that resembles the neurons of a human brain. These networks have multiple nodes grouped into an input layer with the value of each input node representing a concept, a cause, or a past physical attribute . These input nodes are in-turn interconnected with other nodes contained in other intermediate layer(s), to an output layer consisting of one or more nodes each representing an effect, a current physical attribute, or a concept. The interconnections between nodes can be preset or adjusted, and can be thought of as a series of weighted averages.
The inputs of a neural network can be thought of representing a series of events (or causes) which result in a series of predictive outputs (or effects). Changing the value of the input of a “trained” neural network, when propagated through the network, will result in a predicted value at the output node. In a Generative AI program, a different type of Neural Network, called Natural Language Processing, is used to convert words into concepts that are capable of being understood by a machine.
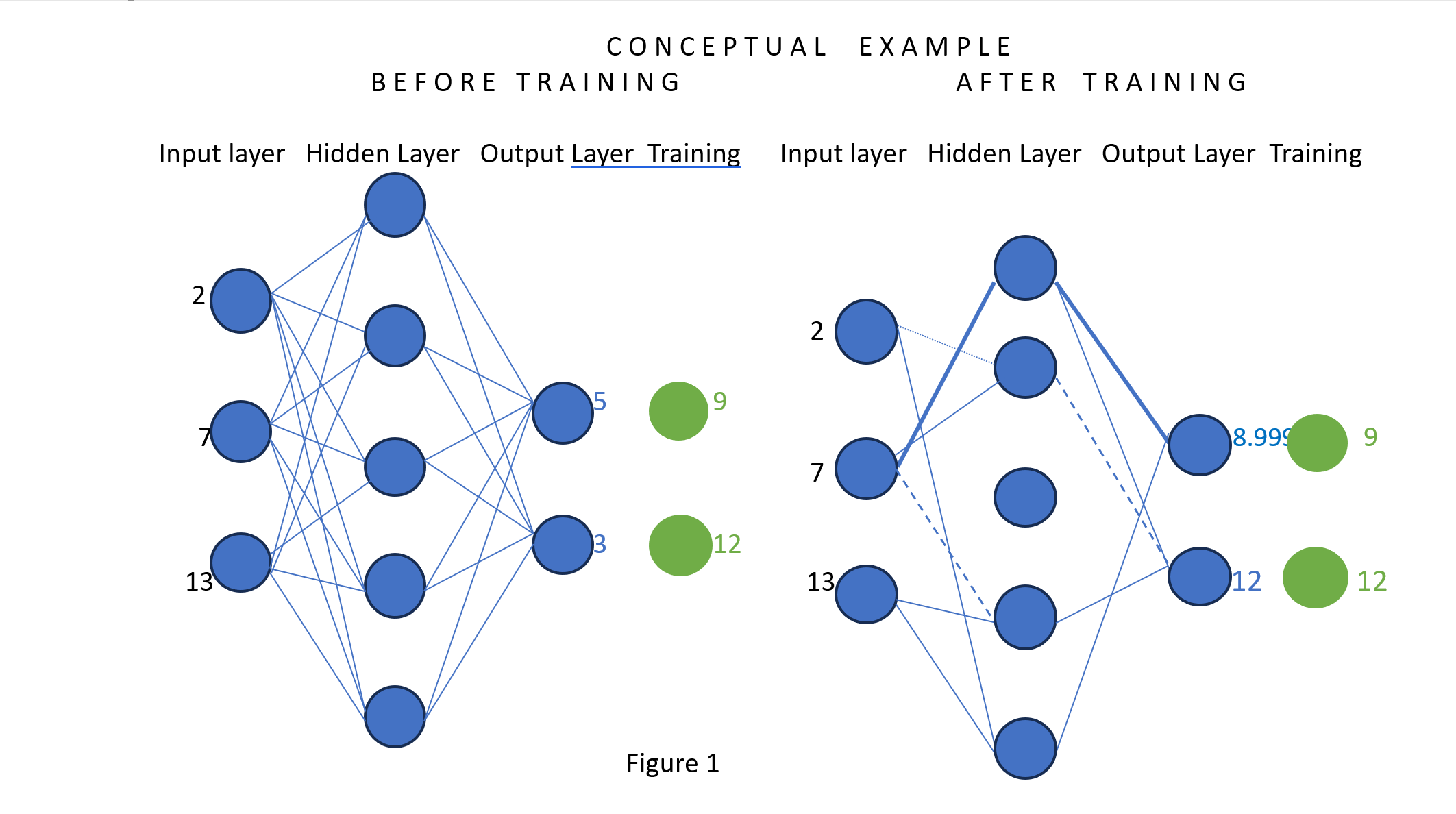
The “training” of a neural network involves first obtaining a matched set of observable inputs (causes) and observable outputs (effects). The matched set of verbal real world inputs (causes) and outputs (effects) are called training data or a training set. The verbal real world training set would be translated into machine readable format by a neural network application called Natural Language Processing. Figure 1 is an example of untrained and trained neural networks with blue input nodes representing real world inputs (causes) and green output nodes representing associated real world output (effects). The blue output nodes represent calculated effects.
The connections between nodes are assigned weights. In an untrained network all weights are all equal to one. In a partially trained network the weights are less than or equal to one, and some connections may have a zero value. The process of training a neural network is a simple incremental, trial and error, adjustment to the weights of interconnections between notes. Training is a trivial arithmetic process, but a neural network with thousands of nodes (or more) and hundreds of thousands of interconnections is a massive computing problem. The changing of values continues until the value of calculated output nodes is equivalent to the value of the training set output nodes. Once the difference between observed and calculated output values are insignificant, the training process ends and the interconnected weights between the nodes are frozen. Once the neural network is frozen, the assumption is that as inputs change, the resulting propagated output values are predictive. As new data are added to the neural network, retraining may begin with all interconnection values set to one, or the existing network (partially trained) may be retrained with new data.
In the following very, very elementary example (Figure 1) the Blue “Input Layer” and the green “Training” nodes represent the paired Training Data collected by the real-world observation. The initial neural network is set up with one or more hidden nodes. All nodes are initially interconnected with weights equal to one. Training involves a random selection of interconnected weights with the goal that when the system is propagated, the Output layer (blue) is close to equaling the Training layer (green) of the Training Set.
In many ways, a neural network can be viewed as a “black box” with no significant meaning assigned to the hidden layer(s) nor the weights of the interconnected lines to and from the hidden Layer(s).
Because, in a neural network, the information is stored in the hidden layers and the weights of the interconnections between the hidden layer(s) and the Input and output layers, there is generally not a way to scientifically determine cause and effect, just relationships. There are multiple neural networks used in Chat GPT (and other generative AI applications) that contain hundreds of thousands input and output nodes for storing and processing data, as well as hundreds of thousands of input and output nodes for Natural Language Processing to convert verbal into computer data. Because of the nature of neural networks, sometimes stored information, while the concept is stored, it may not exactly reproduced the data. Because of the nature a neural network’s hidden nodes, once data is included in the neural network, it may be very difficult to segregate ownership of data for traditional copyright purposes, and difficult to remove the data concepts.
Observations & Conclusions: The current public iteration of Generative Artificial Intelligence, (ex. OpenAI’s Chat GPT – Chat Generative Pre-Trained Transformer) was launched November 30, 2023, which process our human language and generates a response using forms of neural networks. (Chat GPT v 3 & 4 have had millions of downloads since December.) Chat GPT is one of several Generative AI models that learn the patterns and structure of their input training data by applying neural network machine learning techniques, and then generate new data that has similar characteristics. Multiple neural networks as well and software coded information are used in Chat GPT, which is why, sometimes, results of Chat GPT can be initially suspect. Often the Chat CPT application does not care if it has enough data for its conclusions. For example, some attorneys have used Chat GPT to write a legal brief that looked like it was expertly prepared. However, on closer examination, citations were found to be faulty, resulting in contempt of court citations. Additionally, because most data used to establish training sets is from the public domain (ie, Twitter, Facebook, etc.) it will be difficult to show ownership of data once integrated into a neural network. Because of the massive size of neural networks, most subsequent training of neural networks with new data will be from partially trained neural networks, not with new networks.
ChatGPT will allow companies to create their own proprietary neural network data structures that would integrate into the public side of ChatGPT. While this may in the future satisfy many of the data ownership questions, there seems to be a propensity to leak private data into the public sphere. The questions involving royalties will be problematic and probably require new legal frameworks to address the issues.
There is a data processing axiom, garbage in – garbage out. As Generative AI applications such as ChatGPT become more ubiquitous, the integrity of the public database will become a non-trivial problem. It is suggested that new government sanctioned profession(s) organizations (similar to attorneys and physicians) will need to be created to train professionals to maintain and add to these data sources. Professionals certified by these organizations would agree to abide by a code of ethics, and take continuing education to assure professional integrity.
Disclaimer: This article can be thought of a continuation of my previous Rotary article The AI/ChatGPT Paradigm Shift (https://okcrotary.club/the-ai-chatgpt-paradigm-shift/ ). It has been 20 years since I completed my dissertation on Neural Networks and an analysis of why the results of Neural Network processing was sometimes not totally repeatable. It has been 15 years since I retired from academia and began my real estate career. Additionally, since my dissertation I have had at least two strokes. So, while the concepts presented here are valid for lay consumption, they may not be totally academically sound.